
Document de travail n°917 : Prévoir le commerce mondial en temps réel grâce au machine learning : une approche en trois étapes
Nous prévoyons le commerce mondial à l’aide des méthodes de machine learning, en distinguant entre celles fondées sur les arbres de décision (forêt aléatoire, gradient boosting) et leurs équivalents basés sur les régressions (forêt aléatoire macroéconomique, gradient boosting linéaire). Bien que moins utilisées dans la littérature, ces dernières s’avèrent plus performantes que les techniques basées sur les arbres, ainsi que d’autres techniques linéaires et non linéaires (MCO, Markov-switching, régression quantile). Leur performance est significative et constante à différents horizons. Nous proposons une approche flexible en trois étapes : (étape 1) pré-sélection des variables, (étape 2) extraction de facteurs et (étape 3) régression machine learning. Nous constatons que la pré-sélection et l’extraction de facteurs améliorent de manière significative la précision des prévisions de machine learning. Cette approche en trois étapes est également plus performante que les modèles de référence, tels qu’un modèle à facteurs dynamiques. En plus d’une précision accrue, l’approche est flexible et peut être appliquée de même manière au-delà du commerce mondial.
L'analyse économique en temps réel est souvent confrontée au fait que les indicateurs sont publiés avec des délais importants. Ce problème se pose pour le commerce mondial en volume : l'indicateur le plus précoce est publié par le Centraal Plan Bureau (CPB) environ huit semaines après la fin du mois - ce qui signifie que les données de mars 2023 sont disponibles vers le 25 mai. Comme ces données sont largement utilisées par les économistes, cela pose un problème sur le plan de la politique économique, car les décisions doivent reposer sur des informations concernant le cycle économique actuel. Entre-temps, un certain nombre d'indicateurs sont disponibles. L'objectif de cet article est d'exploiter ces indicateurs avancés pour obtenir une estimation du commerce mondial en volume avant la publication officielle du CPB.
L'une des principales nouveautés de cet article est l'utilisation de techniques d'apprentissage automatique pour la prévision de la période courante (« nowcasting »). Nous distinguons les techniques d'apprentissage automatique basées sur les « arbres » de décision et celles basées sur les régressions linéaires. La première catégorie - basée sur des « arbres » de décision - comprend la « forêt aléatoire » et le « gradient boosting » et est la plus populaire dans la littérature. Cependant, ses performances sont médiocres sur notre ensemble de données, ce qui confirme les conclusions récentes selon lesquels ces techniques pourraient être inadaptées pour traiter les séries temporelles habituelles en macroéconomie, où l’échantillon est généralement très court. En revanche, les techniques basées sur les régressions linéaires – « forêt aléatoire » macroéconomique et « gradient boosting » linéaire - fournissent les prévisions les plus précises. Leurs performances surpassent celles des autres techniques, non seulement d'apprentissage automatique basées sur les arbres de décision, mais aussi les techniques non-linéaires plus traditionnelles (régression par transition de Markov et régression quantile) ainsi que les moindres carrés ordinaires (MCO). Elles le font de manière significative, et uniforme en considérant différents horizons, ensembles de données en temps réel, et états de l'économie.
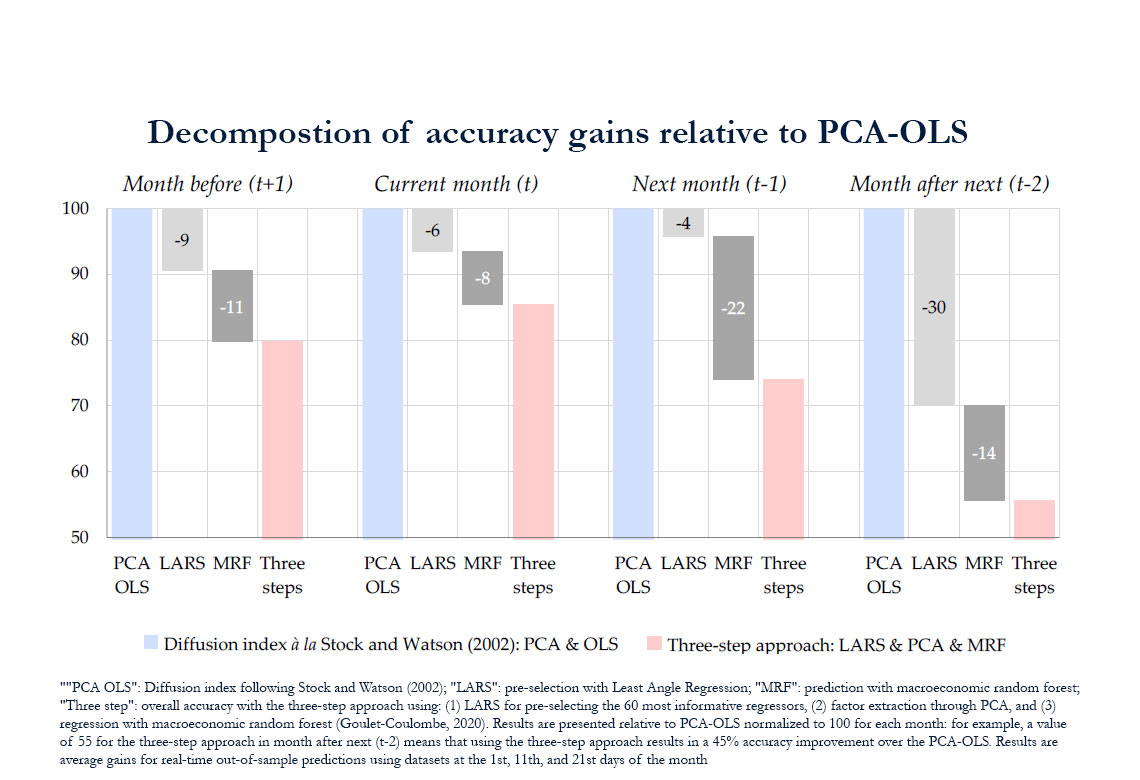
Une deuxième contribution clé consiste à proposer une approche en trois étapes pour les prévisions avec l'apprentissage automatique. L'approche fonctionne de manière séquentielle : (étape 1) une technique de présélection identifie les variables les plus informatives parmi notre base de données de 600 variables ; (étape 2) les variables sélectionnées sont résumées en quelques facteurs ; et (étape 3) les facteurs sont utilisés comme variables explicatives dans la régression du commerce mondial, à l'aide de techniques d'apprentissage automatique. Bien que cette présélection et cette extraction de facteurs aient déjà été utilisées dans la littérature, notre contribution consiste à les utiliser de manière combinée dans le cadre de l'apprentissage automatique. Nous comparons différentes méthodes pour chaque étape : la combinaison la plus performante est formée par la régression de type LARS (pour Least Angle Regression, voir Efron et al., 2004) pour la présélection, l'analyse en composantes principales (ACP) pour l'extraction de facteurs et la forêt aléatoire macroéconomique (Goulet-Coulombe, 2020) pour la régression. La méthode LARS est similaire à la régression de type « step-wise » : lorsqu'il s'agit d’utiliser un grand nombre de régresseurs potentiels, les variables sont incluses pas à pas, mais la méthode garantit que les coefficients de régression sont similaires en valeur absolue lorsque les variables ont la même corrélation avec les résidus.
L'approche en trois étapes surpasse les autres approches de manière significative. Notre approche en trois étapes peut être considérée comme une extension des « indices de diffusion » de Stock et Watson (2002) largement utilisés dans la littérature, qui combine l'extraction de facteurs par ACP et la régression par MCO. Par rapport à un modèle à la Stock et Watson (2002), l'approche en trois étapes produit une une erreur quadratique moyenne (RMSE) inférieure de 26%, les gains de précision provenant à la fois de l'ajout d'une étape de présélection et de l'utilisation de la forêt aléatoire macroéconomique (figure N1). Enfin, nous vérifions que l'approche en trois étapes est plus performante que les modèles les plus courants, tels que le modèle à facteurs dynamiques.
En fin de compte, l'approche en trois étapes peut être considérée comme une méthode « pas-à-pas » pour les prévisionnistes désireux d'utiliser des techniques d'apprentissage automatique. Outre l'utilisation de techniques innovantes d'apprentissage automatique, la contribution de ce document réside dans la combinaison de trois étapes (présélection, extraction de facteur, apprentissage automatique). Nous montrons que chaque étape améliore la précision : les approches alternatives qui excluent la présélection, l'extraction de facteurs ou l'apprentissage automatique sont moins performantes de manière significative. Ces résultats contribuent à la littérature croissante sur l'apprentissage automatique en montrant empiriquement que : (i) sur des échantillons courts, les techniques d'apprentissage automatique fonctionnent mieux si les données sont résumées en facteurs au lieu de prendre toutes les séries individuelles comme variables explicatives, et (ii) la précision est encore plus grande si l’on présélectionne uniquement une partie des régresseurs potentiels.
Télécharger la version PDF du document

- Publié le 12/07/2023
- 49 page(s)
- FR
- PDF (982.73 Ko)
Mis à jour le : 12/07/2023 17:10